我能想象到需要使用hadoop streaming的原因:
- 有很多非java的积累代码必须运行在hadoop上;
- 使用其他语言(C/C++)编写mapreduce会比java更节省CPU或内存,或者更快得足以抵消掉hadoop streaming引入的性能开销;
- 有时候使用脚本临时处理任务比较方便;
- 我就是爱使用X语言!!
Hadoop Wiki上已经有一篇很完整介绍 hadoop streaming 的文章了。大抵上会用java写hadoop mapreduce,就对hadoop streaming没什么理解障碍。
假如我有两个脚本,mapcmd 和 reducecmd,分别作为map和reduce的处理函数。则使用hadoop streaming执行这个mapreduce job,命令为:
使用起来跟java写mapreduce程序一样简单(甚至你觉得更简单些)。
Hadoop streaming 通过 stdin/stdout 来在java进程与mapcmd/reducecmd之间传输数据。默认的情况下,将<key,value>按照 "key + \t + value" 的形式传输给 mapcmd/reducecmd;而mapcmd/reducecmd 也必须按照 "key + \t + value" 的形式返回给 java进程。

相对于原生的 java mapreduce接口,唯一不同的是reducecmd每接收一行是<key,value>,而不是<key,[value1,value2,...]>。至于为什么不直接给reducecmd按照 "key\tvalue1,value2,..."类似的形式传过去,初衷无法考证,或许考虑到<key,value>对于脚本来说接口更简单一些。
总而言之,无论是怎么将key和value编码给可执行程序的,甚至通过什么传输给可执行程序的,终究就是一个协议而已。而这一切,完全是在hadoop原生的mapreduce框架之外处理的。
实现上,只要在mapper/reducer处将往返可执行程序的“桥”搭建好即可。因此,hadoop streaming本身就是一个mapreduce程序,跟我们平时所写的java mapreduce程序并无多大差别。
在 hadoop streaming中,扮演“搭桥”角色的 mapper 和 reducer 分别是 PipeMapper 和 PipeReducer。此外,旧的mapreduce接口(即mapred) 中除了Mapper之外,还有一个MapRunnable的接口可以扩展,方便用户扩展调用Mapper的方式(譬如多线程);而没有对应的ReduceRunnable。所以,hadoop streaming中,负责map和可执行程序传输数据的为PipeMapRunner和PipeMapper,负责reduce和可执行程序传输数据的为PipeReducer。
Hadoop streaming 之所以说可以桥接任何可执行程序,是因为:
因此,hadoop streaming并不需要为每种可能的可执行程序开发任何适配接口。不同于hadoop pipes,利用socket和binary编码来进行数据交互,譬如脚本用户是不愿编写过多的代码来接收数据的,自然需要接口库适配(当然,hadoop pipes接口用起来明显自然一点,至于效率是不是更好,则不得而知了)。
hadoop streaming 将数据编码做成可扩展的,下行(Java to STDIN) 的编码由InputWriter负责,默认为TextInputWriter,上行(STDOUT to Java)的编码为OutputReader,默认为TextOutputReader。
PipeMapper和PipeReducer所做的事情是类似的,在进行真正的map和reduce之前,运行用户指定的可执行程序,并启动单独的线程读取程序的stdout,以便在map开始之后进行捕捉。然后map过程中,将数据用InputWriter编码写到可执行程序的stdin。用户进程处理完数据输出到stdout之后,之前启动读取stdout的线程读取到数据,用OutputReader解码写到OutputCollector上面去。其余流程与原生的一致。
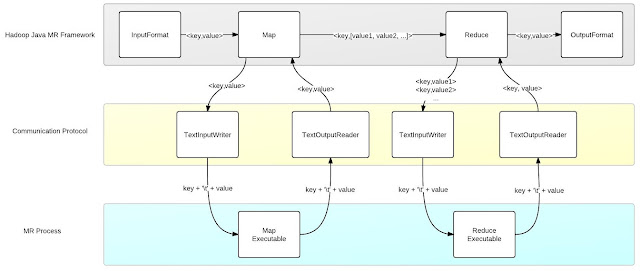

相对于原生的 java mapreduce接口,唯一不同的是reducecmd每接收一行是<key,value>,而不是<key,[value1,value2,...]>。至于为什么不直接给reducecmd按照 "key\tvalue1,value2,..."类似的形式传过去,初衷无法考证,或许考虑到<key,value>对于脚本来说接口更简单一些。
总而言之,无论是怎么将key和value编码给可执行程序的,甚至通过什么传输给可执行程序的,终究就是一个协议而已。而这一切,完全是在hadoop原生的mapreduce框架之外处理的。
实现上,只要在mapper/reducer处将往返可执行程序的“桥”搭建好即可。因此,hadoop streaming本身就是一个mapreduce程序,跟我们平时所写的java mapreduce程序并无多大差别。
在 hadoop streaming中,扮演“搭桥”角色的 mapper 和 reducer 分别是 PipeMapper 和 PipeReducer。此外,旧的mapreduce接口(即mapred) 中除了Mapper之外,还有一个MapRunnable的接口可以扩展,方便用户扩展调用Mapper的方式(譬如多线程);而没有对应的ReduceRunnable。所以,hadoop streaming中,负责map和可执行程序传输数据的为PipeMapRunner和PipeMapper,负责reduce和可执行程序传输数据的为PipeReducer。
Hadoop streaming 之所以说可以桥接任何可执行程序,是因为:
- 使用stdin/stdout做进程间数据交互
- 交互的默认数据编码足够简单
因此,hadoop streaming并不需要为每种可能的可执行程序开发任何适配接口。不同于hadoop pipes,利用socket和binary编码来进行数据交互,譬如脚本用户是不愿编写过多的代码来接收数据的,自然需要接口库适配(当然,hadoop pipes接口用起来明显自然一点,至于效率是不是更好,则不得而知了)。
hadoop streaming 将数据编码做成可扩展的,下行(Java to STDIN) 的编码由InputWriter负责,默认为TextInputWriter,上行(STDOUT to Java)的编码为OutputReader,默认为TextOutputReader。
PipeMapper和PipeReducer所做的事情是类似的,在进行真正的map和reduce之前,运行用户指定的可执行程序,并启动单独的线程读取程序的stdout,以便在map开始之后进行捕捉。然后map过程中,将数据用InputWriter编码写到可执行程序的stdin。用户进程处理完数据输出到stdout之后,之前启动读取stdout的线程读取到数据,用OutputReader解码写到OutputCollector上面去。其余流程与原生的一致。
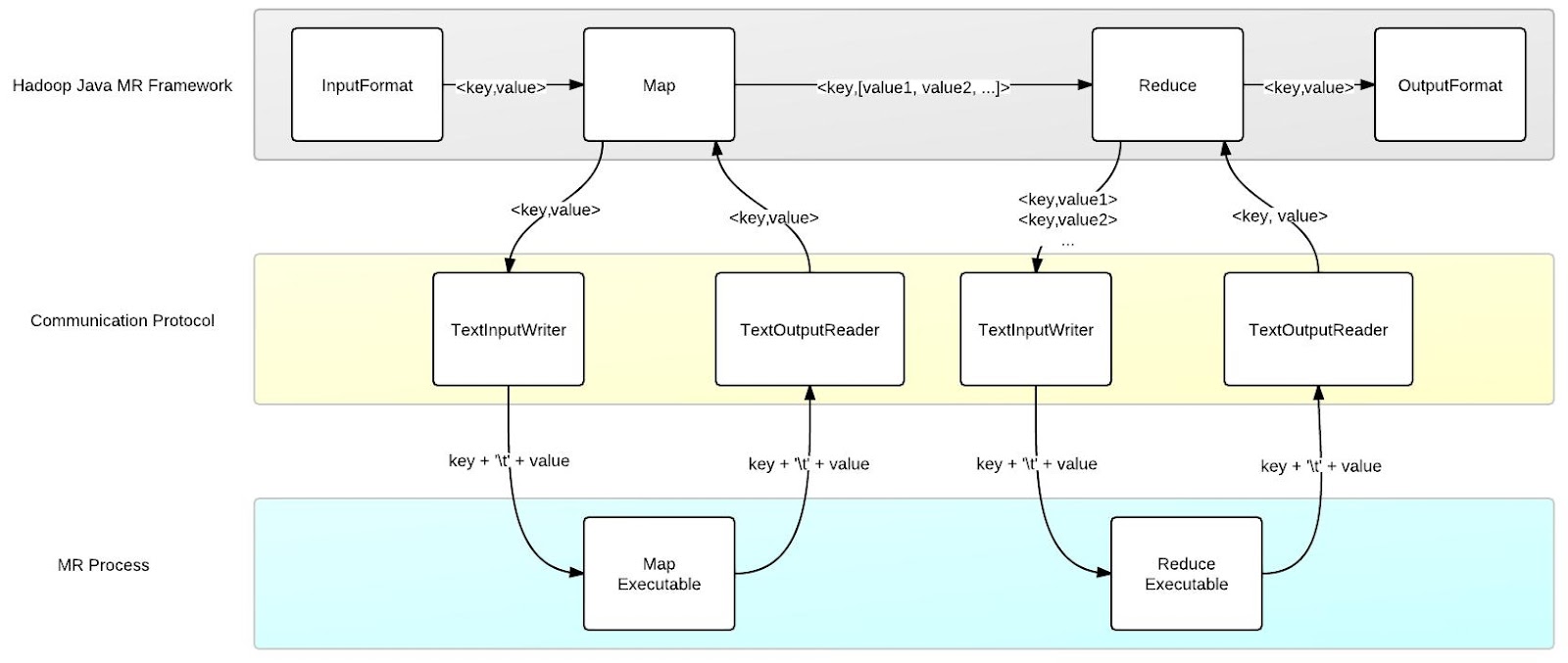
Hadoop pipes 的实现层次与hadoop streaming 相差不大。主要的差别在于hadoop pipes隐藏了数据交互细节,而hadoop streaming将这个交给了用户。